Some reading before starting:
Before setting out, getting some basic concepts about snort is important.
This deployment with be in Network Intrusion Detection System (NIDS) mode – which performs detection and analysis on traffic. See other options and nice and concise introduction: http://manual.snort.org/node3.html.
Rule application order: activation->dynamic->pass->drop->sdrop->reject->alert->log
Again drawing from the snort manual some basic understanding of snort alerts can be found:
[**] [116:56:1] (snort_decoder): T/TCP Detected [**]
116 – Generator ID, tells us what component of snort generated the alert
Eliminating false positives
After running pulled pork and using the default snort.conf there will likely be a lot of false positives. Most of these will come from the preprocessor rules. To eliminate false positives there are a few options, to retain maintainability of the rulesets and the ability to use pulled pork, do not edit rule files directly. I use the following steps:
- Create an alternate startup configuration for snort and barnyard2 without -D (daemon) and barnyard2 config that only writes to stdout, not the database. – Now we can stop and start snort and barnyard2 quickly to test our rule changes.
- Open up the relevant documentation, especially for preprocessor tuning – see the ‘doc’ directory in the snort source.
- Have some scripts/traffic replays ready with traffic/attacks you need to be alerting on
- Iterate through reading the doc, making changes to snort.conf(for preprocessor config), adding exceptions/suppressions to snort’s threshold.conf or PulledPork’s disablesid, dropsid, enablesid, modifysid confs for pulled pork and running the IDS to check for false positives.
If there are multiple operating systems in your environment, for best results define ipvars to isolate the different OSs. This will ensure you can eliminate false positives whilst maintaining a tight alerting policy.
HttpInspect
From doc: HttpInspect is a generic HTTP decoder for user applications. Given a data buffer, HttpInspect will decode the buffer, find HTTP fields, and normalize the fields. HttpInspect works on both client requests and server responses.
Global config –
Custom rules
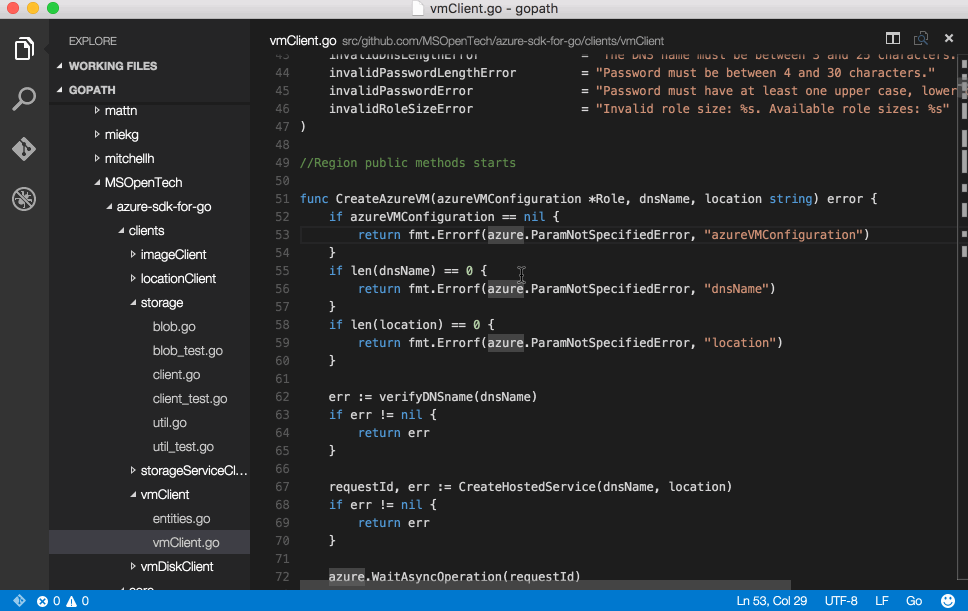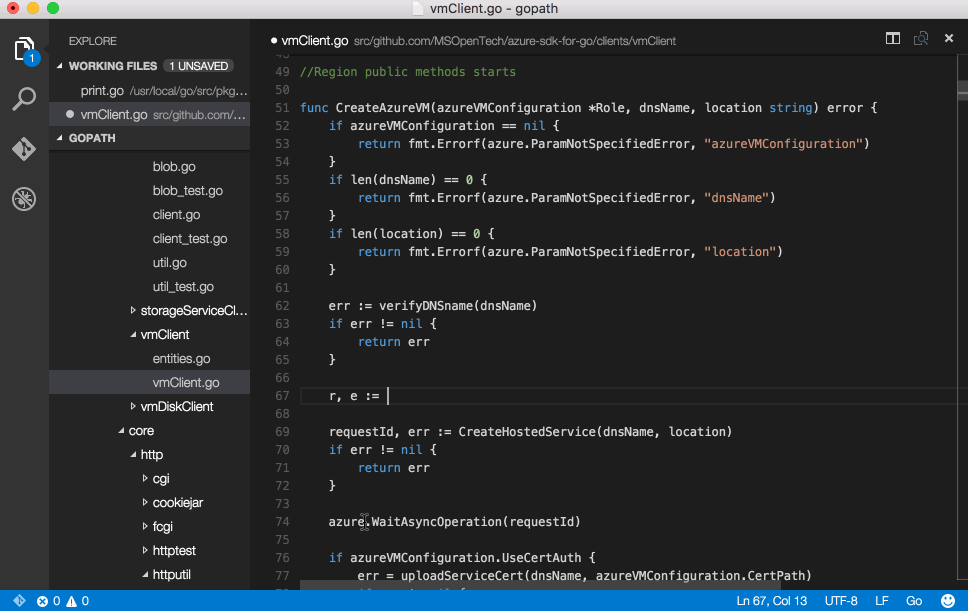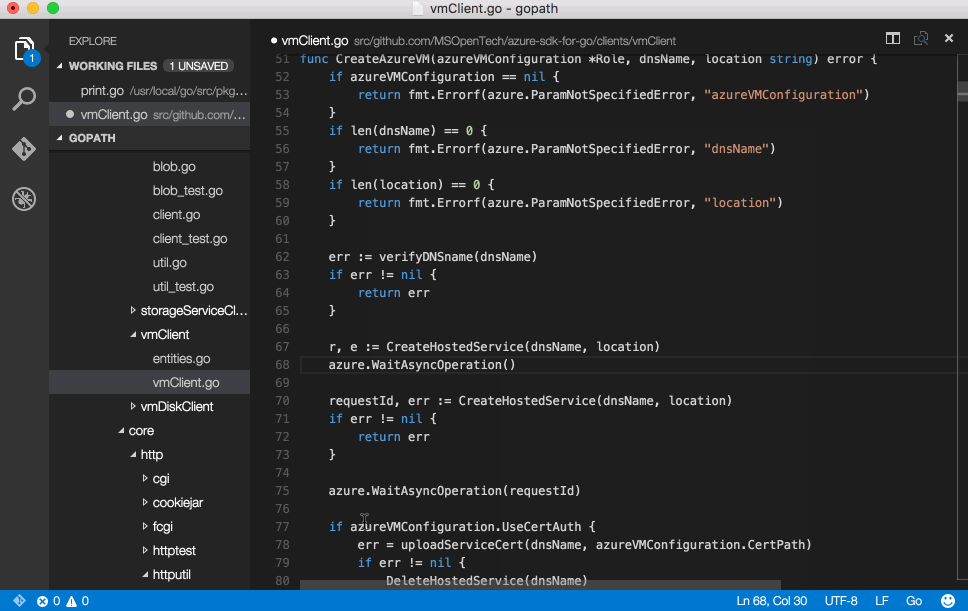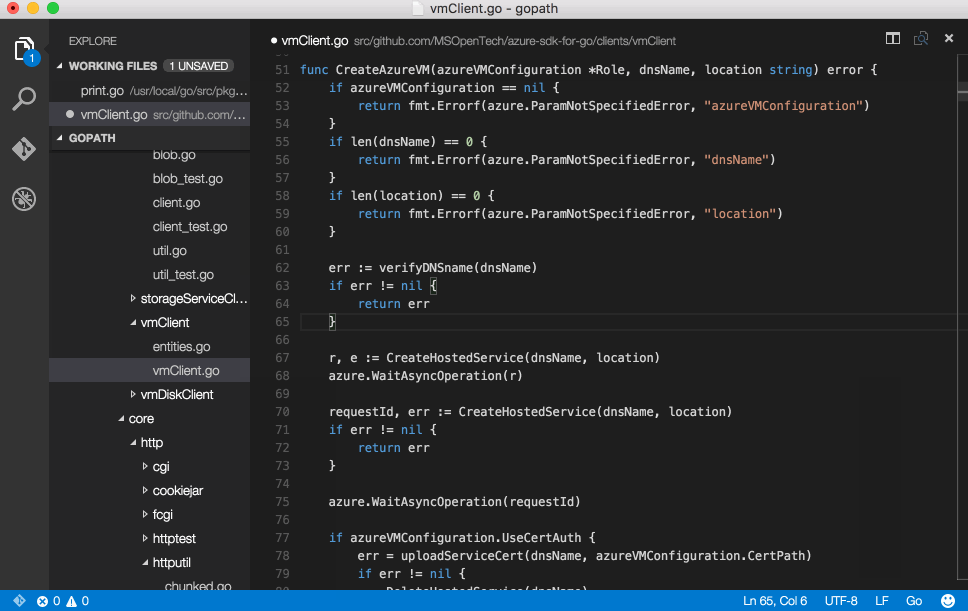
Writing custom rules using snorts lightweight rules description language enables snort to be used for tasks beyond intrusion detection. This example will look at writing a rule to detect Internet Explorer 6 user agents connecting to port 443.
Rule Headers -> [Rule Actions, Protocols, IP Addresses and ports, Direction Operator,
Rule Options -> [content: blah;msg: blah;nocase;HTTP_header;]
Rule Option categories:
- general – informational only — msg:, reference:, gid:, sid:, rev:, classtype:, priority:, metadata:
- payload – look for data inside the packet —
- content: set rules that search for specific content in the packet payload and trigger a response based on that data (Boyer-Moore pattern match). If there is a match anywhere within the packets payload the remainder of the rule option tests are performed (case sensitive). Can contain mixed text and binary data. Binary data is represented as hexdecimal with pipe separators — (content:”|5c 00|P|00|I|00|P|00|E|00 5c|”;). Multiple content rules can be specified in one rule to reduce false positives. Content has a number of modifiers: [nocase, rawbytes, depth, offset, distance, within, http_client_body, http_cookie, http_raw_cookie, http_header, http_raw_header, http_method, http_uri, http_raw_uri, http_stat_code, http_stat_msg, fast_pattern.
- non-payload – look for non-payload data
- post-detection – rule specific triggers that are enacted after a rule has been matched