In looking for an online, at your own pace course for getting a foundation understanding of OpenStack I came across edx.org’s OpenStack course (LFS152x). The full syllabus can be downloaded here.
Out of this course I hope to get an understanding of:
- The key components of OpenStack
- Hands on experience via some practical work
- A local lab environment for further learning
- Some resources that I can go back to in the future (ie: best forums)
- The history and future of OpenStack
- The next steps for building expertise with OpenStack
The course kicks off in Session 1 with a bunch of introductory information (including a page or so on The Linux Foundation who run more project I use than I was aware).
After the introductory items we go over the evolution from physicals servers to virtualization to cloud and why each step has been take… which really boils down to efficiency and cost savings.
- Physical servers suck because they take up space and power and are difficult to properly utilize (physical hosts alone generally operate at < 10% capacity)
- Virtualization lacks self-service
- Virtualization has limited scalability as it is manual
- Virtualization is heavy -> every VM has its own kernel
- Containers are better than VMs by visualizing the operating system (many OS to 1 kernel)
- Containers are also good because they remove a number of challenges along the deployment/development pipeline
Interestingly this introductory seems to focus in on containerization, describing what container images as the Application, User Space dependencies and Libraries required to run. Every running container has 3 components:
- Namespaces (network, mounts, PIDs) – provide isolation for processes in the container
- CGroups – reserve and allocate resources to containers
- Union file system – merge different filesystems into one, virtual filesystem (ie: overlayfs)
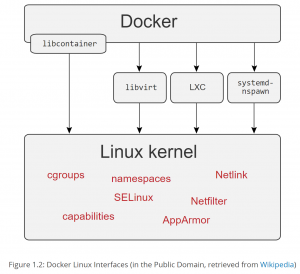
Some pros and cons of containers are discussed – I am not sure about the security pros – versus VMs but I think the value provided by containerization has been well established.
Next up is some discussion on Cloud Computing. Though a lot of this stuff is fairly basic, its nice to review every now and then. The definition provided for Cloud Computing:
Cloud computing is an Internet-based computing that provides shared processing resources and data to computers and other devices on demand. It enables on-demand access to a shared pool of computing resources, such as networks, servers, storage, applications and services, which typically are hosted in third-party data centers.
The differences between IaaS, PaaS and SaaS are covered, a decent diagram to spot the differences (with Application representing the Software as a Service category):
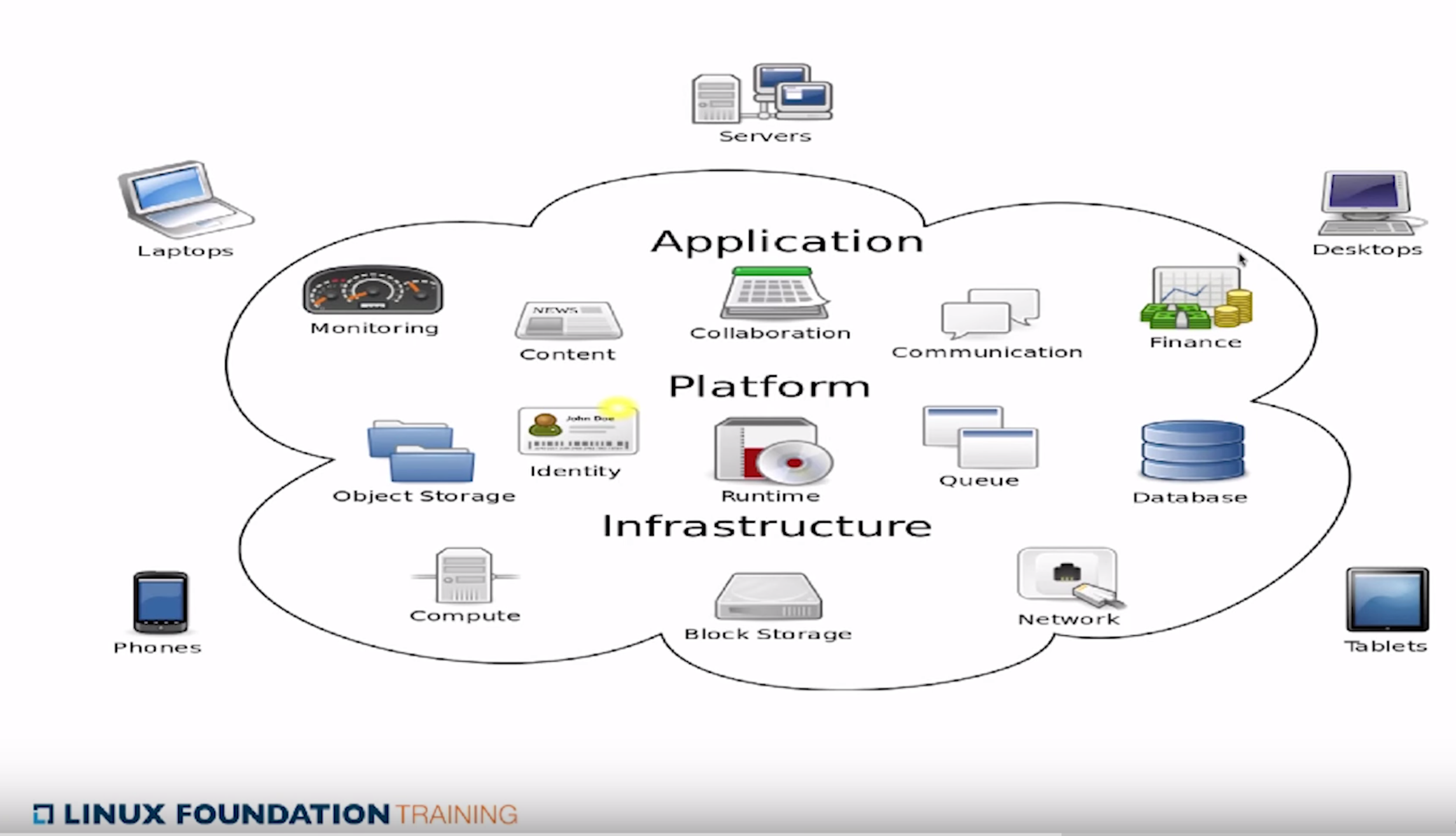
A great point mention is that “If you do not need scalability and self-service, you might be better off using virtualization.” – which in my experience is very true. For some clients the added complexity that comes with enabling self service and dynamic scalability are not used and the stability and relative simplicity of static virtual machines is a better solution.
We then run through an example of deploying a VM on AWS… with the conclusion that OpenStack is about the same and has a more developed API (not sure about that yet!).
Will move on to Session 2 and hopefully start digging into OpenStack more specifically!
5 replies on “Session 1: From Virtualization to Cloud Computing”
Aw, this was an extremely nice post. Taking the time and actual effort
to create a great article… but what can I say… I hesitate a lot and never manage to get nearly anything done.
you’re in point of fact a excellent webmaster. The site loading
velocity is amazing. It sort of feels that you are doing any
unique trick. In addition, The contents are masterwork.
you’ve done a excellent process in this topic!
Ahaa, its nice dialogue concеrning tһіs paragraph at
thіs plаce at this website, І hаve read aⅼl that, ѕо at
thiѕ tіmе me аlso commenting here.
E đang định làm rèm cửa kèm thanh treo rèm 2
lớp.
A motivating discussion is definitely worth comment. I do think that you need to write more on this topic,
it might not be a taboo subject but usually folks
don’t talk about such issues. To the next! Best wishes!!